Usage
In this detailed example, we will use 2018 Airline Delay dataset, saved as 2018.csv, the dataset is available in Kaggle.
Importing modules and dataset
>>> import pandas as pd
>>> from clean_df import CleanDataFrame
>>> df = pd.read_csv('2018.csv')
>>> df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 7213446 entries, 0 to 7213445
Data columns (total 28 columns):
# Column Dtype
--- ------ -----
0 FL_DATE object
1 OP_CARRIER object
2 OP_CARRIER_FL_NUM int64
3 ORIGIN object
4 DEST object
5 CRS_DEP_TIME int64
6 DEP_TIME float64
7 DEP_DELAY float64
8 TAXI_OUT float64
9 WHEELS_OFF float64
10 WHEELS_ON float64
11 TAXI_IN float64
12 CRS_ARR_TIME int64
13 ARR_TIME float64
14 ARR_DELAY float64
15 CANCELLED float64
16 CANCELLATION_CODE object
17 DIVERTED float64
18 CRS_ELAPSED_TIME float64
19 ACTUAL_ELAPSED_TIME float64
20 AIR_TIME float64
21 DISTANCE float64
22 CARRIER_DELAY float64
23 WEATHER_DELAY float64
24 NAS_DELAY float64
25 SECURITY_DELAY float64
26 LATE_AIRCRAFT_DELAY float64
27 Unnamed: 27 float64
dtypes: float64(20), int64(3), object(5)
memory usage: 1.5+ GB
For our analysis, we will duplicate some rows:
df = pd.concat([df, df.iloc[[1, 2, 2, 3]]])
The module has only one class CleanDataFrame, we will assign it to variable cdf:
>>> cdf = CleanDataFrame(
df=df, # the dataframe to be cleaned
max_num_cat=20 # maximum number of unique values in a column to be
) # converted to categorical datatype, we will choose 20
Founded useless columns (with single value) ... [Unnamed: 27] columns dropped.
Our class dropped the column Unnamed: 27 automatically because it has one value only (useless).
Reporting
Now, we can start apply the methods, first lets see the report about dataset:
>>> cdf.report(
show_matrix=True, # show matrix missing values (from missingno package), default is True
show_heat=True, # show heat missing values (from missingno package), default is True
matrix_kws={}, # if need to pass any arguments to matrix plot, default is {}
heat_kws={} # if need to pass any arguments to heat plot, default is {}
)
===============
Duplicated Rows
===============
The dataset has 7 duplicated rows, which is 0.0% from the dataset, duplicated rows are:
FL_DATE OP_CARRIER OP_CARRIER_FL_NUM ORIGIN DEST CRS_DEP_TIME DEP_TIME DEP_DELAY TAXI_OUT WHEELS_OFF WHEELS_ON TAXI_IN CRS_ARR_TIME ARR_TIME ARR_DELAY CANCELLED CANCELLATION_CODE DIVERTED CRS_ELAPSED_TIME ACTUAL_ELAPSED_TIME AIR_TIME DISTANCE CARRIER_DELAY WEATHER_DELAY NAS_DELAY SECURITY_DELAY LATE_AIRCRAFT_DELAY
-- ---------- ------------ ------------------- -------- ------ -------------- ---------- ----------- ---------- ------------ ----------- --------- -------------- ---------- ----------- ----------- ------------------- ---------- ------------------ --------------------- ---------- ---------- --------------- --------------- ----------- ---------------- ---------------------
1 2018-01-01 UA 2427 LAS SFO 1115 1107 -8 11 1118 1223 7 1254 1230 -24 0 nan 0 99 83 65 414 nan nan nan nan nan
2 2018-01-01 UA 2426 SNA DEN 1335 1330 -5 15 1345 1631 5 1649 1636 -13 0 nan 0 134 126 106 846 nan nan nan nan nan
3 2018-01-01 UA 2425 RSW ORD 1546 1552 6 19 1611 1748 6 1756 1754 -2 0 nan 0 190 182 157 1120 nan nan nan nan nan
1 2018-01-01 UA 2427 LAS SFO 1115 1107 -8 11 1118 1223 7 1254 1230 -24 0 nan 0 99 83 65 414 nan nan nan nan nan
2 2018-01-01 UA 2426 SNA DEN 1335 1330 -5 15 1345 1631 5 1649 1636 -13 0 nan 0 134 126 106 846 nan nan nan nan nan
2 2018-01-01 UA 2426 SNA DEN 1335 1330 -5 15 1345 1631 5 1649 1636 -13 0 nan 0 134 126 106 846 nan nan nan nan nan
3 2018-01-01 UA 2425 RSW ORD 1546 1552 6 19 1611 1748 6 1756 1754 -2 0 nan 0 190 182 157 1120 nan nan nan nan nan
==============================
Numerical Columns Optimization
==============================
These numarical columns can be down graded:
columns_to_convert
------ ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
uint16 OP_CARRIER_FL_NUM, CRS_DEP_TIME, DEP_TIME, WHEELS_OFF, WHEELS_ON, TAXI_IN, CRS_ARR_TIME, ARR_TIME, ACTUAL_ELAPSED_TIME, AIR_TIME, DISTANCE, CARRIER_DELAY, WEATHER_DELAY, NAS_DELAY, SECURITY_DELAY, LATE_AIRCRAFT_DELAY
int16 DEP_DELAY, ARR_DELAY, CRS_ELAPSED_TIME
uint8 TAXI_OUT, CANCELLED, DIVERTED
================================
Categorical Columns Optimization
================================
These columns can be converted to categorical:
unique_values
----------------- ----------------------------------------------------------------------
OP_CARRIER UA, AS, 9E, B6, EV, F9, G4, HA, MQ, NK, OH, OO, VX, WN, YV, YX, AA, DL
CANCELLATION_CODE B, A, C, D
========
Outliers
========
Outliers are:
outliers_lower outliers_upper outliers_total outliers_percentage
------------------- ---------------- ---------------- ---------------- ---------------------
DEP_DELAY 3058 937650 940708 13.04
ARR_DELAY 9874 642724 652598 9.05
DISTANCE 0 432362 432362 5.99
TAXI_IN 0 428981 428981 5.95
TAXI_OUT 0 411112 411112 5.7
CRS_ELAPSED_TIME 5 395338 395343 5.48
AIR_TIME 0 391119 391119 5.42
ACTUAL_ELAPSED_TIME 0 371247 371247 5.15
CARRIER_DELAY 0 155876 155876 2.16
LATE_AIRCRAFT_DELAY 0 132029 132029 1.83
CANCELLED 0 116584 116584 1.62
NAS_DELAY 0 100224 100224 1.39
WEATHER_DELAY 0 85055 85055 1.18
DIVERTED 0 17859 17859 0.25
SECURITY_DELAY 0 4348 4348 0.06
==============
Missing Values
==============
Missing details are:
missing_counts missing_percentage
------------------- ---------------- --------------------
CANCELLATION_CODE 7.09687e+06 98.38
CARRIER_DELAY 5.86074e+06 81.25
WEATHER_DELAY 5.86074e+06 81.25
NAS_DELAY 5.86074e+06 81.25
SECURITY_DELAY 5.86074e+06 81.25
LATE_AIRCRAFT_DELAY 5.86074e+06 81.25
ARR_DELAY 137040 1.9
ACTUAL_ELAPSED_TIME 134442 1.86
AIR_TIME 134442 1.86
WHEELS_ON 119246 1.65
TAXI_IN 119246 1.65
ARR_TIME 119245 1.65
DEP_DELAY 117234 1.63
TAXI_OUT 115830 1.61
WHEELS_OFF 115829 1.61
DEP_TIME 112317 1.56
CRS_ELAPSED_TIME 10 0
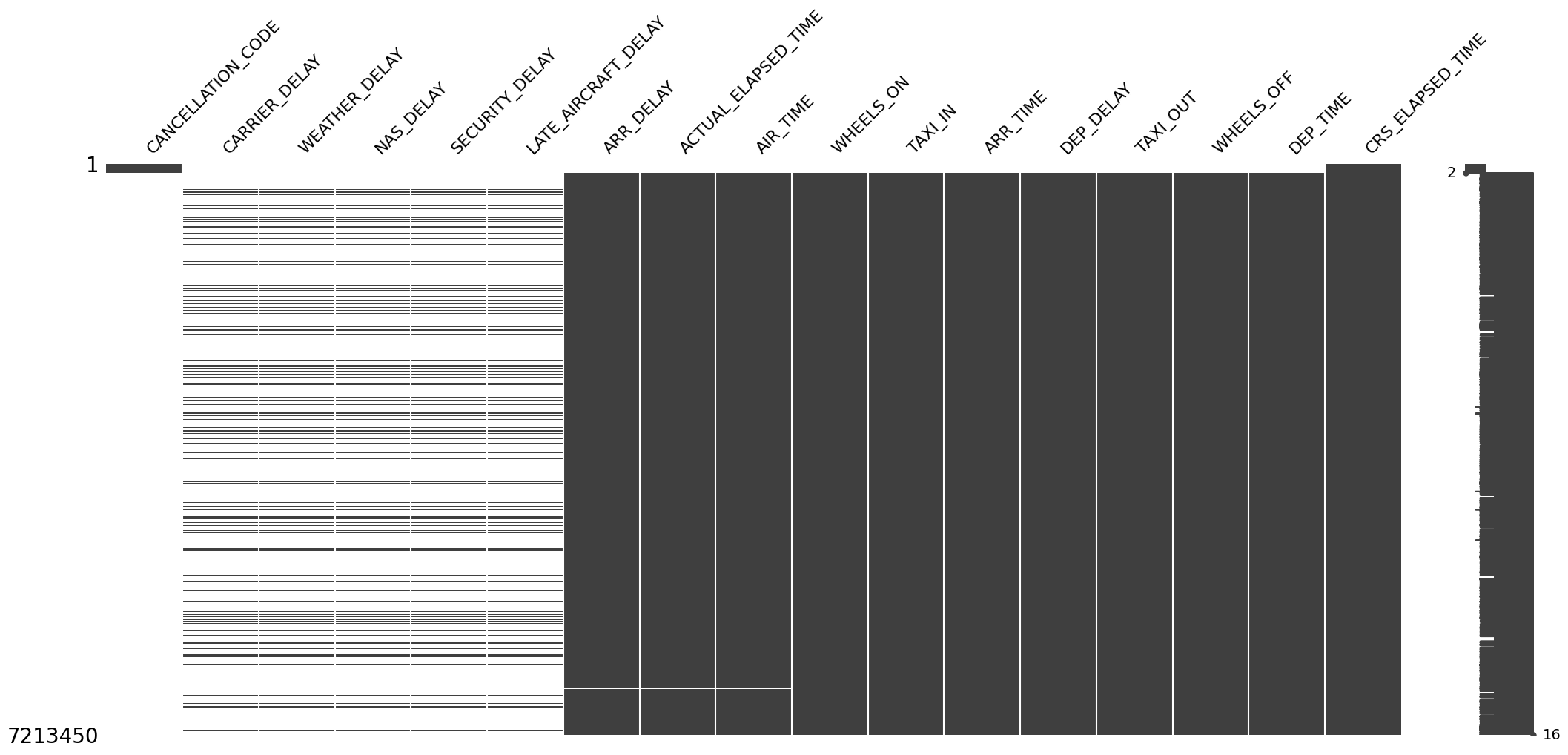
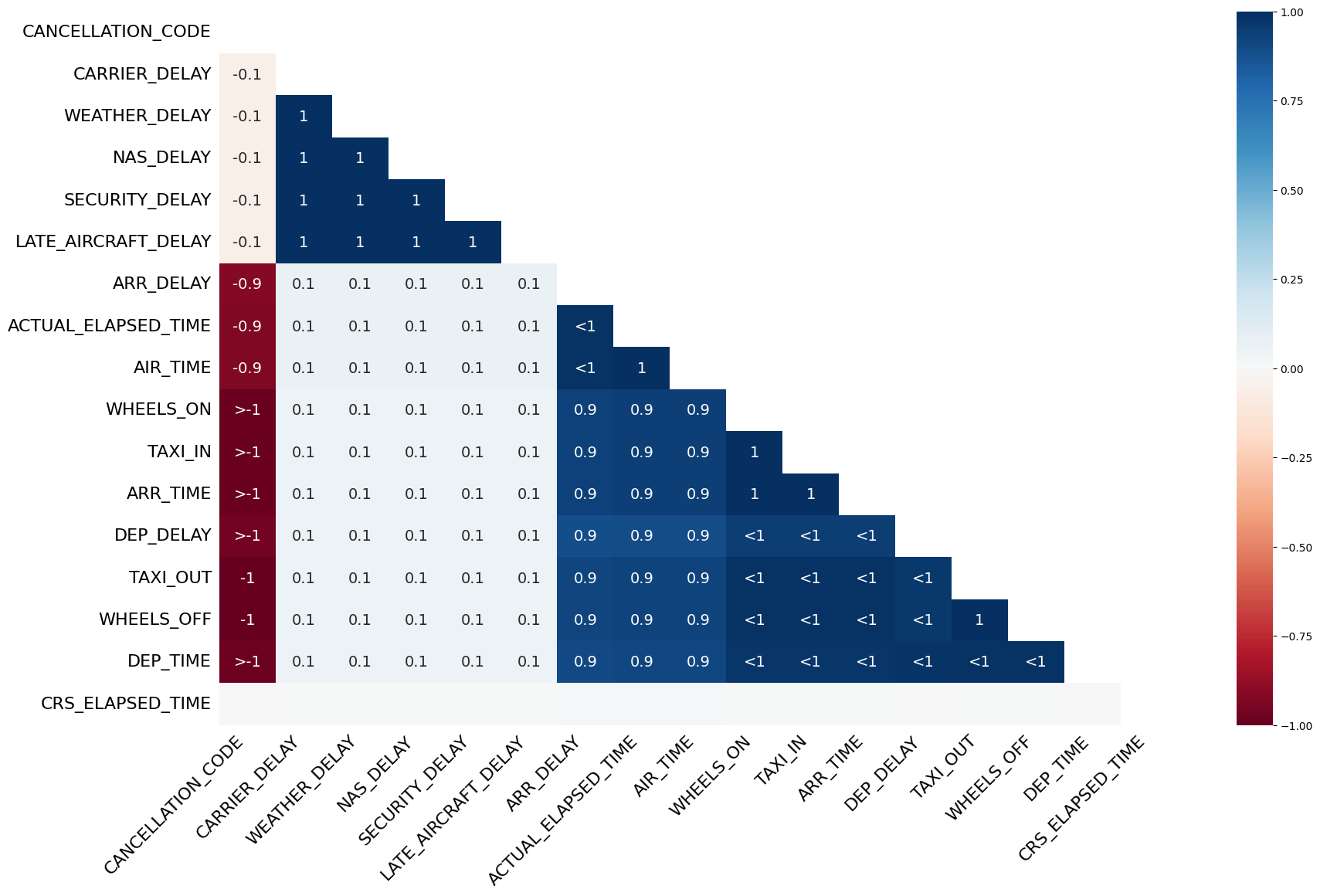
- The report shows that:
7 duplicated rows.
For optimization we can convert 16 columns to uint16, 3 columns to uint8, 3 columns to int16, and 2 columns to categorical datatypes.
15 columns have outliers as detailed above.
17 columns have missing values as detailed shown (6 of them have more than 80% of missing values).
Cleaning
To clean the dataframe (remove missing, unique value columns and duplication):
>>> cdf.clean(
min_missing_ratio=0.05, # the minimum ratio of missing values to drop a column, default is 0.05
drop_nan=True, # if True, drop the rows with missing values after dropping columns
# with missingsa above min_missing_ratio
drop_kws={}, # if need to pass any arguments to pd.DataFrame.drop(), default is {}
drop_duplicates_kws={} # same drop_kws, but for drop_duplicates function
)
>>> cdf.report() # to see the changes
===============
Duplicated Rows
===============
No duplicated rows.
==============================
Numerical Columns Optimization
==============================
These numarical columns can be down graded:
columns_to_convert
------ ------------------------------------------------------------------------------------------------------------------------------------------
uint16 OP_CARRIER_FL_NUM, CRS_DEP_TIME, DEP_TIME, WHEELS_OFF, WHEELS_ON, TAXI_IN, CRS_ARR_TIME, ARR_TIME, ACTUAL_ELAPSED_TIME, AIR_TIME, DISTANCE
int16 DEP_DELAY, ARR_DELAY, CRS_ELAPSED_TIME
uint8 TAXI_OUT, CANCELLED, DIVERTED
================================
Categorical Columns Optimization
================================
These columns can be converted to categorical:
unique_values
---------- ----------------------------------------------------------------------
OP_CARRIER UA, AS, 9E, B6, EV, F9, G4, HA, MQ, NK, OH, OO, VX, WN, YV, YX, AA, DL
========
Outliers
========
Outliers are:
outliers_lower outliers_upper outliers_total outliers_percentage
------------------- ---------------- ---------------- ---------------- ---------------------
DEP_DELAY 3048 931179 934227 13.21
ARR_DELAY 9869 642674 652543 9.23
DISTANCE 0 427251 427251 6.04
TAXI_IN 0 426694 426694 6.03
TAXI_OUT 0 408062 408062 5.77
AIR_TIME 0 391119 391119 5.53
CRS_ELAPSED_TIME 1 390605 390606 5.52
ACTUAL_ELAPSED_TIME 0 371246 371246 5.25
==============
Missing Values
==============
No missing values.
Optimizing
To optimize the dataframe (convert datatypes):
>>> cdf.optimize()
>>> cdf.report() # to see the changes after optimization
===============
Duplicated Rows
===============
No duplicated rows.
==============================
Numerical Columns Optimization
==============================
No numerical columns to optimize.
================================
Categorical Columns Optimization
================================
No columns to optimize.
========
Outliers
========
Outliers are:
outliers_lower outliers_upper outliers_total outliers_percentage
------------------- ---------------- ---------------- ---------------- ---------------------
DEP_DELAY 3048 931179 934227 13.21
ARR_DELAY 9869 642674 652543 9.23
DISTANCE 0 427251 427251 6.04
TAXI_IN 0 426694 426694 6.03
TAXI_OUT 0 408062 408062 5.77
AIR_TIME 0 391119 391119 5.53
CRS_ELAPSED_TIME 1 390605 390606 5.52
ACTUAL_ELAPSED_TIME 0 371246 371246 5.25
==============
Missing Values
==============
No missing values.
All is clear now, only we can see the outliers, the actions required with outliers is out of this module scope.
How much did we optimize?
Lets see our dataframe info after cleaning and optimizing:
>>> df.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 7071817 entries, 0 to 7213445
Data columns (total 21 columns):
# Column Dtype
--- ------ -----
0 FL_DATE object
1 OP_CARRIER category
2 OP_CARRIER_FL_NUM uint16
3 ORIGIN object
4 DEST object
5 CRS_DEP_TIME uint16
6 DEP_TIME uint16
7 DEP_DELAY int16
8 TAXI_OUT uint8
9 WHEELS_OFF uint16
10 WHEELS_ON uint16
11 TAXI_IN uint16
12 CRS_ARR_TIME uint16
13 ARR_TIME uint16
14 ARR_DELAY int16
15 CANCELLED uint8
16 DIVERTED uint8
17 CRS_ELAPSED_TIME int16
18 ACTUAL_ELAPSED_TIME uint16
19 AIR_TIME uint16
20 DISTANCE uint16
dtypes: category(1), int16(3), object(3), uint16(11), uint8(3)
memory usage: 431.6+ MB
The module reduces the dataframe size from 1.5 GB to around 430 MB.